It's all a blur
If you follow information security discussions on the internet, you might have heard that blurring an image is not a good way of redacting its contents. This is supposedly because blurring algorithms are reversible.
But then, it’s not wrong to scratch your head. Blurring amounts to averaging the underlying pixel values. If you average two numbers, there’s no way of knowing if you’ve started with 1 + 5 or 3 + 3. In both cases, the arithmetic mean is the same and the original information appears to be lost. So, is the advice wrong?
Well, yes and no! There are ways to achieve non-reversible blurring using deterministic algorithms. That said, in many cases, the algorithm preserves far more information than would appear to the naked eye — and does it in a pretty unexpected way. In today’s article, we’ll build a rudimentary blur algorithm and then pick it apart.
One-dimensional moving average
If blurring is the same as averaging, then the simplest algorithm we can choose is the moving mean. We take a fixed-size window and replace each pixel value with the arithmetic mean of n pixels in its neighborhood. For n = 5, the process is shown below:
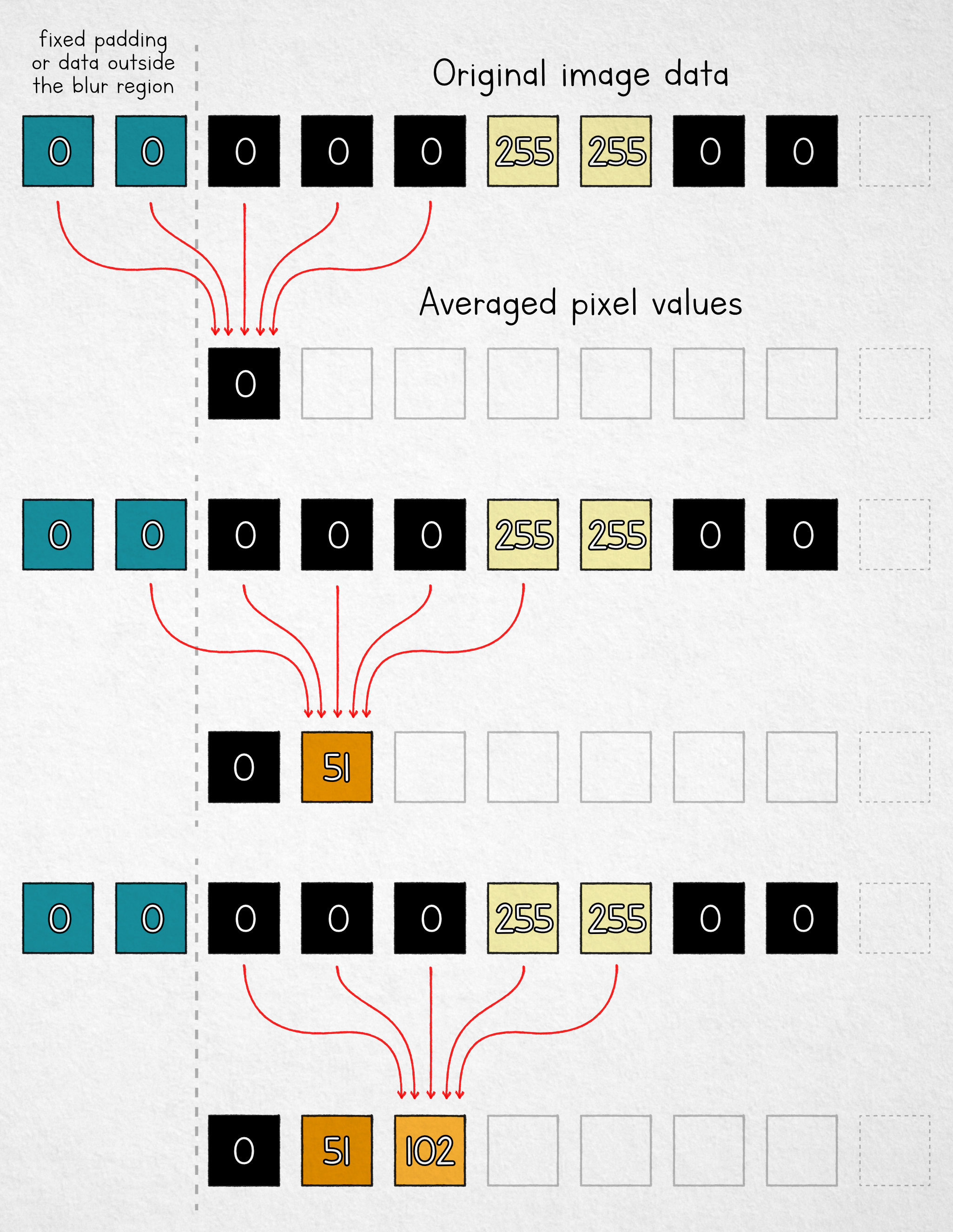
Note that for the first two cells, we don’t have enough pixels in the input buffer. We can use fixed padding, “borrow” some available pixels from outside the selection area, or simply average fewer values near the boundary. Either way, the analysis doesn’t change much.
Let’s assume that we’ve completed the blurring process and no longer have the original pixel values. Can the underlying image be reconstructed? Yes, and it’s simpler than one might expect!
We start at the left boundary (x = 0). Recall that we calculated the first blurred pixel like by averaging the following pixels in the original image:
Next, let’s have a look at the blurred pixel at x = 1. Its value is the average of:
We can easily turn these averages into sums by multiplying both sides by the number of averaged elements (5):
Note that the underlined terms repeat in both expressions; this means that if we subtract them from each other, we end up with just:
The value of img(-2) is known to us: it’s one of the fixed padding pixels used by the algorithm. Let’s shorten it to c. We also know the values of blur(0) and blur(1): these are the blurred pixels that can be found in the output image. This means that we can rearrange the equation to recover the original input pixel corresponding to img(3):
The recovered value allows us to successively reconstruct additional pixels using the same approach, although we end up with some gaps that need to be resolved with a second pass that moves in the opposite direction in the pixel buffer. Instead of going down that path, let’s make the math a bit simpler with a good-faith tweak to the averaging algorithm.
Right-aligned moving average
The modification that will make our life easier is to shift the averaging window so that one of its ends is aligned with where the computed value will be stored:
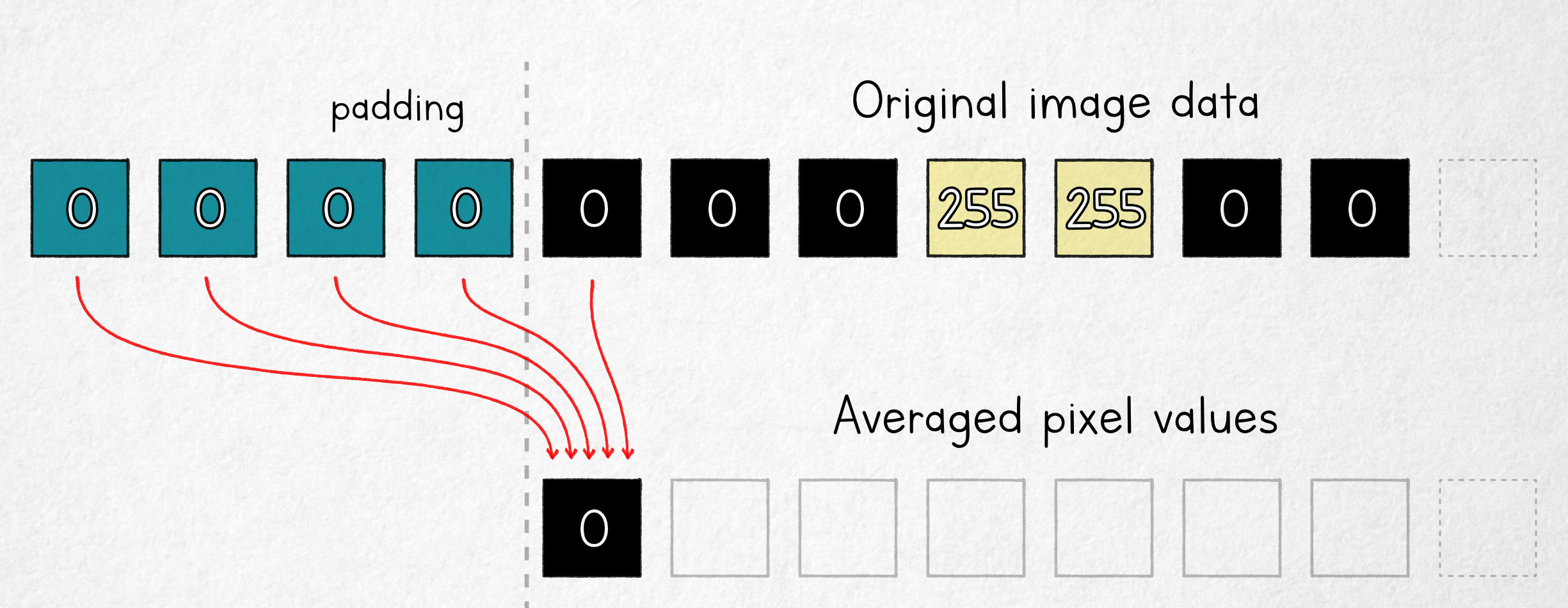
In this model, the first output value is an average of four fixed padding pixels (c) and one original image pixel; it follows that in the n = 5 scenario, the underlying pixel value can be computed as:
If we know img(0), we now have all but one of the values that make up blur(1), so we can find img(1):
The process can be continued iteratively, reconstructing the entire image.
In the illustration below, the left panel shows a detail of The Birth of Venus by Sandro Botticelli; the right panel is the same image ran through the right-aligned moving average blur algorithm with a 151-pixel averaging window that moves only in the x direction:

Now, let’s take the blurry image and attempt the reconstruction method outlined above — computer, ENHANCE!

This is rather impressive. The image is noisier than before as a consequence of 8-bit quantization of the averaged values in the intermediate blurred image. Nevertheless, even with a large averaging window, fine detail — including individual strands of hair — could be recovered and is easy to discern.
Into the second dimension
The problem with our blur algorithm is that it averages pixel values only in the x axis; this gives the appearance of motion blur or camera shake.
The simplest way to address the issue without redoing the math is to apply the filter in the x axis and, follow with a complementary pass in the y axis, and then perform two recovery passes in the matching order.
Unfortunately, this amount of averaging causes the contribution of the original pixel value to be quantized so severely that the reconstructed image is overwhelmed by noise:

That said, if we’re set on devising an adversarial blur filter, we can fix the problem by weighting the original pixel a bit more heavily in the calculated mean. If the averaging window has a size W and the current-pixel bias factor is B, we can write the following formula:
The following shows the result of a two-stage X-Y blur for W = 200 and B = 30:

Surely, there’s no coming back from tha— COMPUTER, ENHANCE!

Remarkably, the information “hidden” in the blurred image survives being saved in a lossy image format. The top row shows images reconstituted from an intermediate image saved as a JPEG at 95%, 85%, and 75% quality settings:

The bottom row shows less reasonable quality settings of 50% and below; at that point, the reconstructed image begins to resemble abstract art.
For more weird algorithms, click here. Thematic catalog of posts on this site can be found on this page.